Irmin-containers : An introduction
13 Aug 2020Irmin-containers is a library of ready-to-use mergeable data structures implemented using Irmin. What are mergeable data structures? Mergeable data structures, in simple words, are data structures with concepts of git applied to them. Basically, data structures with version control. We can perform a lot of git-like operations like cloning, merging, etc. In this blog, I will briefly explain the different data structures implemented and how to use the Irmin-containers.
Motivation
Irmin is a very powerful library which enables managing mergeable data structures. But unfortunately, it is accompanied with a lot of complexity, especially for a simple user. There have been many attempts to reduce this complexity and provide a ready-to-use containers library in the past few years. Irmin-containers is also of the same spirit and is based on a similar library Ezirmin. Irmin-containers can be viewed as a re-implementation of Ezirmin. But, the thing which really sets it apart is that it is the first such implementation which has been upstreamed to the main Irmin repository.
Installation
To install Irmin-containers, please refer to the installation instructions given here. We will be using utop to look at examples from Irmin-containers. If you wish to follow along, refer to the installion instructions here to install utop.
Irmin
Before we can look at Irmin-containers, we must first understand how Irmin works. Irmin, in very simple words, is a library to create and manage mergeable data structures. This definition does not capture its entirety but this is enough to understand this blog. We will look at some of the features of Irmin in this section.
Irmin store
Irmin manages all the data using key-value stores, which we shall call as Irmin stores. In Irmin stores, the keys are usually hierarchial paths and the values are the data stored in the store. The key must be provided every time the store is read or written to. Each Irmin store is associated with a branch and as a result, all branch operations like cloning, merging, etc., will involve these Irmin stores. All branches are maintained in a repository. Every repository when created will have the master branch by default.
Content addressable store
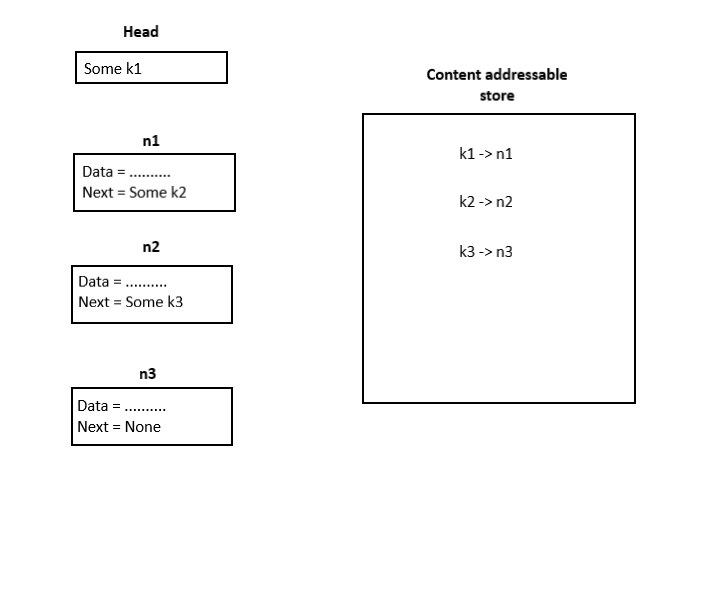
The Irmin store is implemented using two lower level stores: the key store and the content addressable store. The content addressable store maintains the objects whereas the key store maps the keys (provided while accessing Irmin store) to the content addressable store. We can directly use the content addressable store as well. When a new value has to added, the store takes the value, creates a key and stores it. It returns this created key, which corresponds to the value which we stored. This feature makes it suitable to use for maintaining linked lists. This is done as follows. First, the node is created along with the required data. Next, the node is stored in the content addressable store. The corresponding key returned will act as the pointer to that node and suitable updates can be made. The image below shows a linked list with three nodes maintained using a content addressable store.
Backend
We talked about the stores supported by Irmin in the previous two subsections. A natural question which arises is where is all this data stored? In order to store all the data, we need a storage place called backend. The backend is characterized by features such as the place of storage, the metadata maintained, etc. Irmin provides support for multiple backends and supports custom backends too!
Type and Contents
In order to support these special features of branching and merging for data structures, Irmin requires the user to specify the types which will be stored in a certain format. For most stores (apart from Irmin store), the input type must be provided according to the signature Irmin.Type.S. The signature is as follows:
module type S = sig (* Signature of Irmin.Type.S *)
type t
val t : t Irmin.Type.t
end
The type t which you see is the normal OCaml type of the values you want to store. The val t is the equivalent of the type t in Irmin, which we shall call as Irmin type. How can we construct Irmin types? We can do so by using the values and functions provided in the module Irmin.Type. There are equivalent Irmin types for some base OCaml types like int, char, string, etc. Apart from these base types, we can construct records, variants and recursive types using the functions specified in that module.
Now let us see how the type must be provided for Irmin stores. As Irmin stores are involved in merging, some extra information regarding how to merge the values is required. The signature which must be used is Irmin.Contents.S.
module type S = sig (* Signature of Irmin.Contents.S *)
type t
val t : t Irmin.Type.t
val merge : t option Irmin.Merge.t
end
The type t is the OCaml type and the val t is the equivalent Irmin type. The third one, val merge, is a specification of how to merge two values. This can be specified using the module Irmin.Merge. We can construct custom merge functions too apart from using those already implemented in the module.
Merging two branches
Merging two branches in Irmin happens through a three-way merge similar to git. This happens as follows: a common ancestor of the two branches, called Least Common Ancestor (LCA), is computed. The merge takes place using the current state of the two branches and the LCA, based on the rules specified (through val merge as seen in the previous subsection). When we look at the data structures, I will explain the merging rules for each of them.
Irmin_containers
We will now look at how to use Irmin-containers. Along with that, we will also look at a few features of Irmin-containers as well as learn a bit about using Irmin.
Starting up
Let us begin by starting utop.
$ utop
Next we need to load the Irmin-containers library. Before that, we need to load two dependent libraries, namely digestif and checkseum. Two implementations of each are available: C and OCaml. Here, I will be using the C implementations for both the libraries.
utop # #require "digestif.c";;
utop # #require "checkseum.c";;
utop # #require "irmin-containers";;
open Lwt.Infix
Now we are ready to start using Irmin-containers.
Counter
The very first data strcuture which we will look at is the int64 counter. Counter module supports the following functions: increment, decrement and read. First let us look at how to create a counter.
Backends
Before we can create any store (in the present context, for the data structure) in Irmin, we need to think about one important thing: which backend to use? Irmin-containers library comes with functors(or modules) which are pre-instantiated with two backends: the in-memory backend using Irmin_mem (named Mem) and the Unix FS backend using Irmin_unix.FS (named FS). In case a different backend is required, a separate Make functor is available.
Let us use the in-memory backend to create the counter.
utop # module C = Irmin_containers.Counter.Mem;;
Configuration
Now that we have created a counter, we can look at how to perform operations on it. To do that, we need to create a repo, which comes with the master branch (which is associated with an Irmin store). For all such store related functions, all data structures in Irmin-containers have a module Store of type Irmin.S. The function used to create a repo is Store.Repo.v. Let us check its type.
utop # C.Store.Repo.v;;
- : Irmin.config -> C.Store.repo Lwt.t = <fun>
As you can see, it requires a value of type Irmin.config. This value corresponds to the configuration required by the repo and branches. We can create a configuration using Irmin_mem.config or Irmin_git.config. As we are the in-memory backend here, we will use Irmin_mem.config to create the repo. (Note: FS backend requires the configuration created using Irmin_git.config).
utop # let repo = C.Store.Repo.v (Irmin_mem.config ());;
val repo : C.Store.repo Lwt.t = <abstr>
Finally let us retrieve the master branch (actually, the store associated with it; so it will be the 'master store') from the repo.
utop # let master = repo >>= C.Store.master;;
val master : C.Store.t Lwt.t = <abstr>
Basic Operations
Let us now perform some operations on our counter. First, we will examine the types of these functions.
utop # C.inc;;
- : ?by:int64 ->
?info:Irmin.Info.f -> path:C.Store.key -> C.Store.t -> unit Lwt.t
= <fun>
utop # C.dec;;
- : ?by:int64 ->
?info:Irmin.Info.f -> path:C.Store.key -> C.Store.t -> unit Lwt.t
= <fun>
utop # C.read;;
- : path:C.Store.key -> C.Store.t -> int64 Lwt.t = <fun>
In all the functions, C.Store.t refers to an Irmin store (like the master store). The labelled argument path of type C.Store.key corresponds to the key provided to the store for reading and writing. In Irmin-containers, the key (or path) is of type string list. The optional argument by is used to specify the amount by which the counter must be incremented/decremented. If nothing is specified, the increment/decrement value is set to 1L. The other optional argument info can be viewed as the equivalent of commit info in git. Now that we have understood the function types, let us see some examples.
utop # let inc_dec_eg () =
master >>= fun m ->
C.inc ~path:["cntr"] m >>= fun () -> (* increment by 1 *)
C.dec ~path:["cntr"] ~by:5L m >>= fun () -> (* decrement by 5 *)
C.dec ~path:["cntr"] m >>= fun () -> (* decrement by 1 *)
C.inc ~path:["cntr"] ~by:8L m >>= fun () -> (* increment by 8 *)
C.read ~path:["cntr"] m;; (* read the counter *)
utop # Lwt_main.run(inc_dec_eg ());;
- : int64 = 3L
Let us verify the answer. The initial counter value is 0L. The sequence of operations applied to the counter are +1L, -5L, -1L, +8L. So the final answer must be 3L which matches our output.
Clone and merge
Now we will look at some store related operations, namely cloning and merging. Cloning a counter produces another counter with the same current value. Merging two counters to produce one counter happens as follows: let v1 and v2 be the values of the two counters and old be the value of their LCA. The change in each counter as compared to the LCA is v1 - old and v2 - old respectively. The total change from the value old as registered by the two counters is (v1 - old) + (v2 - old). To get the final merged value, we add this change to old and we get the final counter value as v1 + v2 -old. Let us look at an example.
utop # Lwt_main.run(master >>= C.read ~path:["cntr"]);; (* Read the initial value of the master branch counter *)
- : int64 = 3L
utop # let clone = master >>= fun m -> C.Store.clone ~src:m ~dst:"clone";; (* Create a clone *)
val clone : C.Store.t Lwt.t = <abstr>
utop # Lwt_main.run(clone >>= C.inc ~path:["cntr"] ~by:2L);; (* Increment clone counter by 2 *)
utop # Lwt_main.run(clone >>= C.read ~path:["cntr"]);; (* Verify the value *)
- : int64 = 5L
utop # Lwt_main.run(master >>= C.dec ~path:["cntr"] ~by:3L);; (* Decrement master counter by 3 *)
utop # Lwt_main.run(master >>= C.read ~path:["cntr"]);; (* Verify the value *)
- : int64 = 0L
utop # let merge () = (* Merge clone counter into master counter and read the value *)
master >>= fun m ->
clone >>= fun c ->
C.Store.merge_into c ~into:m ~info:(Irmin_unix.info "Merging clone into master") >>= function
| Error _ -> failwith "Error while merging"
| Ok _ -> C.read ~path:["cntr"] m;;
utop # Lwt_main.run(merge ());;
- : int64 = 2L
First let us understand the functions clone and merge_into. clone has two labelled arguments: src which is the counter which will be cloned and dst which is the branch associated with clone. In Irmin-containers, branches are specified through strings. In this example, the cloned counter is associated to “clone”. merge_into takes the two counters, one of them passed with label into (the merged value will be in this counter) and commit info. Let us now verify the merged value. The values of master and clone are 0L and 5L respectively. Their LCA is the point at which clone counter was created. So the LCA value is 3L. So according to our formula above, the final value is 2L which matches our answer.
Last-write-wins (LWW) register
The next data structure which we will look at is the last write wins (LWW) register. It is a register which holds the most recently written value. To create a LWW register, the user is required to provide the type of content which will be stored in the counter, through a module of type Irmin.Type.S. The two operations which are supported are read and write. When two registers are merged, the value among the two branches which is written last is chosen. In the (extemely unlikely) event that the two timestamps are equal, then the value which is greater is chosen (the compare function which is implicitly encoded in the Irmin type is used).
Timestamp
To determine which value was written last, we need to keep track of when it was written, i.e, we need a timestamp. A method to obtain timestamps can be specified through a module with the signature Irmin_containers.Time.S.
module type S = sig
include Irmin.Type.S
val now : unit -> t
end
The signature tells us that any type which can be expressed as an Irmin type can be used as a timestamp. The function now returns the timestamp for the value which is currently being written to the register. It is important that the timestamp method is monotonic to ensure the correct working of the register. Also it is assumed that if a timestamp t1 is greater than another timestamp t2 (as given by the compare function in-built with the Irmin type), then t1 refers to a time later than t2 and the entry with t1 will be stored.
Irmin-containers has an implementation, Time.Machine, for obtaining timestamp using Mtime. The pre-instantiated functors, Mem and FS are also instantiated with Time.Machine. Now let us look at a simple example.
utop # module Int_type = struct (* Irmin.Type.S version of int *)
type t = int
let t = Irmin.Type.int
end;;
utop # module R = Irmin_containers.Lww_register.Mem(Int_input);; (* Create a integer LWW register *)
utop # let lww_eg () =
R.Store.Repo.v (Irmin_mem.config ()) >>= R.Store.master >>= fun t ->
R.write ~path:["lww"] t 10 >>= fun () -> (* Write 10 *)
R.write ~path:["lww"] t 20 >>= fun () -> (* Write 20 *)
R.read ~path:["lww"] t;; (* Read the register *)
utop # Lwt_main.run(lww_eg ());;
- : int option = Some 20
Blob log
The third data structure which we will look at is the blob log. It is a log which is internally maintained as a single unit (or blob), like a list. Appending an entry and reading the entire log are the two operations which are available for the blob log. The type of log entries specified and a timestamping method are required to create the blob log. The timestamping method is already pre-instantiated in Mem and FS.
Merge semantics is as follows: The newer entries in both the logs as compared to the LCA are found out, merged in descending order of timestamps and then appended to the LCA log. Merging takes O(n) time where n is the number of entires in the log.
utop # module Str = struct
type t = string
let t = Irmin.Type.string
end;;
utop # module B = Irmin_containers.Blob_log.Mem(Str);;
utop # let blob_eg () =
B.Store.Repo.v (Irmin_mem.config ()) >>= B.Store.master >>= fun m ->
B.append ~path:["blob"] m "First message" >>= fun () ->
B.append ~path:["blob"] m "Second message" >>= fun () ->
B.read_all ~path:["blob"] m;;
utop # Lwt_main.run(blob_eg ());;
- : string list = ["Second message"; "First message"]
Let us at how append takes place internally. When there is a new entry to be appended, the entire log is first de-serialized, then the log entry is added and finally the log is serialized again. Due to this, the append takes O(n) time where n is the number of log entries.
Linked log
The final data structure which is currently available in Irmin-containers is the linked log. In this implementation, the log is maintained in the form of a linked list. So, in addition to the requirements of the blob log, a content addressable store maker is required to create a linked log. Irmin-containers requires the store maker to be provided along with the configuration for the store. As this requires a configuration, Mem and FS are not instantiated with any content addressable store maker. The module to specify the content addressable store maker must have the following signature:
module type Cas_maker = sig
module CAS_Maker : Irmin.CONTENT_ADDRESSABLE_STORE_MAKER
val config : Irmin.config
end
Now let us look at how to create a linked log. This time I will use the FS backend for a change.
utop # module CAS = struct (* module of type Cas_maker *)
module CAS_Maker =Irmin.Content_addressable (Irmin_unix.FS.Append_only)
let config = Irmin_git.config "/tmp/linked_log"
end;;
utop # module L = Irmin_containers.Linked_log.FS(CAS)(Str)();;
Linked log supports appending log entries, retrieving a cursor to the head entry (a cursor can be viewed as a pointer to a log entry), reading a specified number of items from the cursor and reading the entire log. Compared to the blob log, append here takes O(1) time as the only work which needs to be done is adding a node at the head of the linked list. The way merging takes place is quite involved and hence I will not discuss it in detail here but would like to remark that merging is O(1). We will look at an example of reading one entry at a time from the log.
utop # let rec print_log cursor =
L.read ~num_items:1 cursor >>= function (* Retrieve one item *)
| ([], cur) -> Printf.printf "-- The end --\n"; Lwt.return_unit (* No more items *)
| ([h], cur) -> Printf.printf "%s\n" h; print_log cur (* Print this item and recursively call the function on the next item's cursor *)
| _ -> failwith "Too many items retrieved";;
utop # let linked_log_eg () =
L.Store.Repo.v (Irmin_git.config "/tmp/linked_log") >>=
L.Store.master >>= fun m ->
L.append ~path:["log"] m "Entry 1" >>= fun () ->
L.append ~path:["log"] m "Entry 2" >>= fun () ->
L.append ~path:["log"] m "Entry 3" >>= fun () ->
L.get_cursor ~path:["log"] m >>= print_log;;
utop # Lwt_main.run(linked_log_eg ());;
Entry 3
Entry 2
Entry 1
-- The end --
Differences between linked log and blob log
| Linked log | Blog log |
|---|---|
| Stored internally as a linked list | Stored internally as a single unit or blob |
| Consumes more space for maintaining the linked list | Space efficient |
O(1) append |
O(n) append |
| Suitable for big size logs | Suitable for small size logs |
Concluding remarks
Irmin-containers was created with the aim of simplifying the usage of Irmin for beginners as well as make a set of mergeable data structures available, which can be used directly by users instead of coding them up every time. The size of that set is currently four. But one day, when a lot more data structures are added, Irmin-containers can be viewed as the standard template library (STL) of Irmin. Finally, I would like to thank Craig Ferguson for patiently shepherding this work into shape and KC Sivaramakrishnan for guiding me throughout the course of this project.